
DraftKings web scraping project - Part 1/3
Level 5 - SHARP

Do you have a friend who likes betting and would like to sharpen his/her action? Help them on their path by sharing the BowTiedBettor Substack. Win and help win!
Welcome Avatar!
As you’re aware of by now, accurate data is central in the construction and implementation of profitable betting models. In betting, there are two sets of data that are of primary interest:
Historical data - Foundational for learning about the games/teams/markets and thence figuring out the effect certain variables have on outcomes.
Executional data - Necessary to optimize the actual betting process [when, where and how to place your bets].
So far, we haven’t really handled much of the historical data part on our blog/Substack. Well, an introduction to the concept was provided in Bayesian thinking & inference, part 1, but we’ve still got lots and lots of grounds to cover.
Regarding executional data, we’ve mainly been focusing on the collection of it rather than its applications. By familiarizing ourselves with some common web scraping techniques, we’ve so far learnt how to scrape sports betting websites using both browser automation and http request/response procedures.
Today, the idea is to build on our existing knowledge and take up an even deeper dive on the collection of executional data. This will be done by the launch of a new scraping project, namely to construct an odds scraper (compatible with both pregame & live odds + increased functionality to simplify any practical tasks) for DraftKings.
The DraftKings scraping project will be divided into three main segments. In the first one (today) we’ll build a pregame scraper [primarily for the NHL but easily adjusted to include more leagues] which will allow us send one-time requests to the DraftKings servers and thus collect odds throughout the days leading up to the games (in fact it’ll work fine for live odds as well if one-time-requests is all you want). During the second part we will take care of a slighly more involved subject, the mid-game scraping/streaming, and in part three we’ll complement our scraper with methods that are of high practical value, such as sending email notifications and dumping content into Excel files.
Through the completion of this project, we will further deepen our web scraping knowledge, not only with continued http request/response training but also with guidance on a new, more advanced technique, WebSocket scraping. By familiarizing ourselves with the WebSocket protocol (in part 2, next week), we will gain the last piece of knowledge one needs to have a solid understanding of the art of *collecting* data. Thus, after having finalized this project, we’ll finally be ready for a fully practical perspective, focusing on possible applications and use cases for the data.
WebSocket is a communication protocol that allows two-way, realtime communication between clients and servers over the internet. WebSocket communication works by establishing a persistent connection (as opposed to the HTTP request-response structure) between a client and a server, allowing for seamless data transmission in both directions. This makes the protocol ideal for applications that require fast and efficient communication, such as live betting.
Note: Our scraping material assumes that you have some familiarity with Python. If you do not, please get started today. Learning Python is definitely one of the most +EV decisions you can make if you are even remotely interested in earning WIFI-money. Combine Corey Schafer and Automate the Boring Stuff and you will soon be an excellent herpetologist.
Pregame scraping [and live, but no updating stream]
Okay, let’s begin with segment number one, the pregame scraping. A necessary package to follow this guide is requests (a simple & elegant HTTP library) and to install it in your current environment you simply run
pip install requestsin the terminal.
Note: We’ll be using Firefox throughout this project and recommend you do the same. The reason: its built-in JSON-parser & great web dev tools simplifies the scraping process tremendously.
Visit DraftKings, locate the data
Step one is to visit DraftKings and locate the NHL odds. A quick exploration leads to this url. To check from where they’re fetching the data that’s presented to the end user, head into web tools and visit the Networks tab. Sort on Type and scroll down to the json objects. The below picture describes the view you should be presented with.

Click on the requests and inspect them, manually, one by one, until you find the one with the correct NHL data response. Doing this shows that the one named 42133?format=json is the one we’re after, with 42133, the eventGroupId, appearing to be a value/index reserved for NHL content.
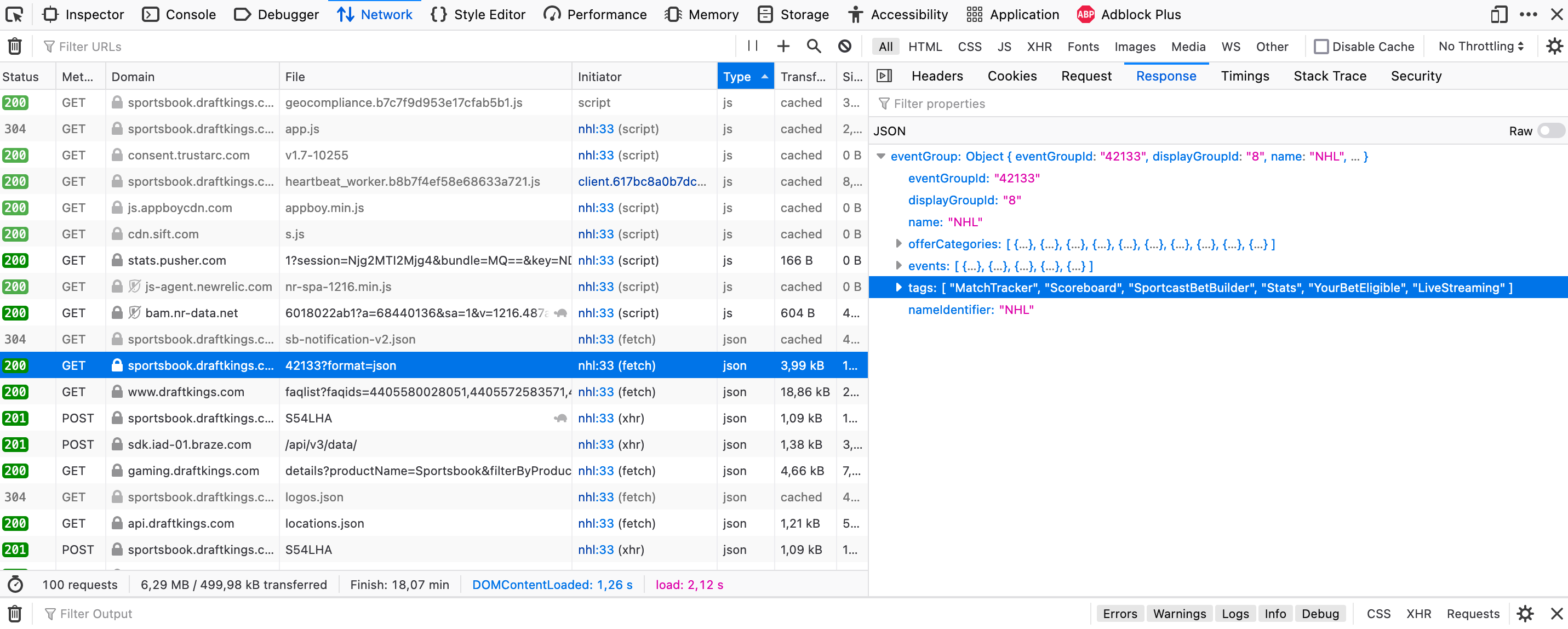
Double clicking the request takes us to this url, which indeed holds all the information we’re interested in. Picture below.

Manually inspecting this JSON [this is where the Firefox JSON-parser comes into play], we find that the odds content for the different games are stored under eventGroup → offerCategories → list object at position 0 → offerSubcategoryDescriptors → list object at position 0 → offerSubcategory → offers. For each object [an object holds all the information for a specific game] in this list of ‘offers’, there are three different elements. One contains the Puck Line, one the Totals and the third one the Moneyline market. Thus, it seems reasonable to loop through those three elements, extract all the information of interest and finally store that information in a clever way.

Time to build!
Note [I]: Since the game plan is to begin betting the NHL at some point, there’s actually more to the creation of both this and future scrapers than purely educational/inspirational material.
Note [II]: Integrating code with Substack posts hasn’t really been optimized yet. If you prefer, you could visit our DraftKings repo and follow along by having the code open in another tab instead (recommended).
To be slightly more sophisticated and structured than we’ve been in earlier scraping posts (and since we intend to actually use this stuff at some point), we’ll build a DraftKings class and then, as we proceed, continuously add new methods to it in order to solve the different subprojects that’ll naturally arise. Accordingly, we create a Python file (draftkings_class.py) and begin building.
The code below defines the DraftKings class and stores the pregame url [will always stay the same] for the given league as an object attribute (an object attribute is basically a variable/element that’s stored together with the object).
import requests
id_dict = {"NHL": "42133", "NFL": "88808", "NBA": "42648"}
class DraftKings:
def __init__(self, league = "NHL"):
"""
Initializes a class object
Include more leagues simply by adding the league with its ID to id_dict above
:league str: Name of the league, NHL by default
"""
self.pregame_url = f"https://sportsbook.draftkings.com//sites/US-SB/api/v5/eventgroups/{id_dict[league]}?format=json"Now, to begin coding the actual scraper, we create our first class method, a get_pregame_odds which will send a get request to the url above, parse the JSON, collect the sought information/data for all the available pregame markets and return the result. Code with comments below, or if you prefer, on Github.
import requests
from traceback import print_exc
def get_pregame_odds(self) -> list:
"""
Collects the market odds for the main markets [the ones listed at the league's main url] for the league
E.g. for the NHL, those are Puck Line, Total and Moneyline
Returns a list with one object for each game
:rtype: list
"""
# List that will contain dicts [one for each game]
games_list = []
# Requests the content from DK's API, loops through the different games & collects all the material deemed relevant
response = requests.get(self.pregame_url).json()
games = response['eventGroup']['offerCategories'][0]['offerSubcategoryDescriptors'][0]['offerSubcategory']['offers']
for game in games:
# List that will contain dicts [one for each market]
market_list = []
for market in game:
try:
market_name = market['label']
if market_name == "Moneyline":
home_team = market['outcomes'][0]['label']
away_team = market['outcomes'][1]['label']
# List that will contain dicts [one for each outcome]
outcome_list = []
for outcome in market['outcomes']:
try:
# if there's a line it should be included in the outcome description
line = outcome['line']
outcome_label = outcome['label'] + " " + str(line)
except:
outcome_label = outcome['label']
outcome_odds = outcome['oddsDecimal']
outcome_list.append({"label": outcome_label, "odds": outcome_odds})
market_list.append({"marketName": market_name, "outcomes": outcome_list})
except:
# if there was a problem with a specific market, continue with the next one...
# for example odds for totals not available as early as the other markets for NBA
# games a few days away
print_exc()
print()
continue
games_list.append({"game": f"{home_team} v {away_team}", "markets": market_list})
return games_listConcisely: the above method collects all the odds data and returns it as a list (with objects following standard JSON-practice). In order not only to check that the scraper functions as intended but also to prepare for future use cases, we continue by constructing a second method, a store_as_json, which has the sole job of dumping the content into a local JSON-file.
Code for the method:
import json
def store_as_json(self, games_list, file_path: str = None):
"""
Dumps the scraped content into a JSON-file in the same directory
:rtype: None, simply creates the file and prints a confirmation
"""
if file_path:
with open(file_path, 'w') as file:
json.dump(games_list, file)
print(f"Content successfully dumped into '{file_path}'")
else:
with open('NHL.json', 'w') as file:
json.dump(games_list, file)
print("Content successfully dumped into 'NHL.json'")Having the two methods get_pregame_odds and store_as_json coded and completed, we’re now in a good position to actually run the scraper and verify that everything works as expected.
Creating a second Python file, draftkings_script.py [a scripting file for usage of the class we’re building in draftkings_class.py], and running the following few lines of code should scrape the available NHL markets and dump all of it into a new file named ‘NHL.json’.
from draftkings_class import DraftKings
dk = DraftKings(league = "NHL")
games = dk.get_pregame_odds()
dk.store_as_json(games)First, running the script seems to work out fine.

Now, the real check is of course performed by heading over to the JSON-file and examining it carefully.
Indeed, as you can see in the picture, the NHL content appears to have been both collected and saved correctly. Great success!
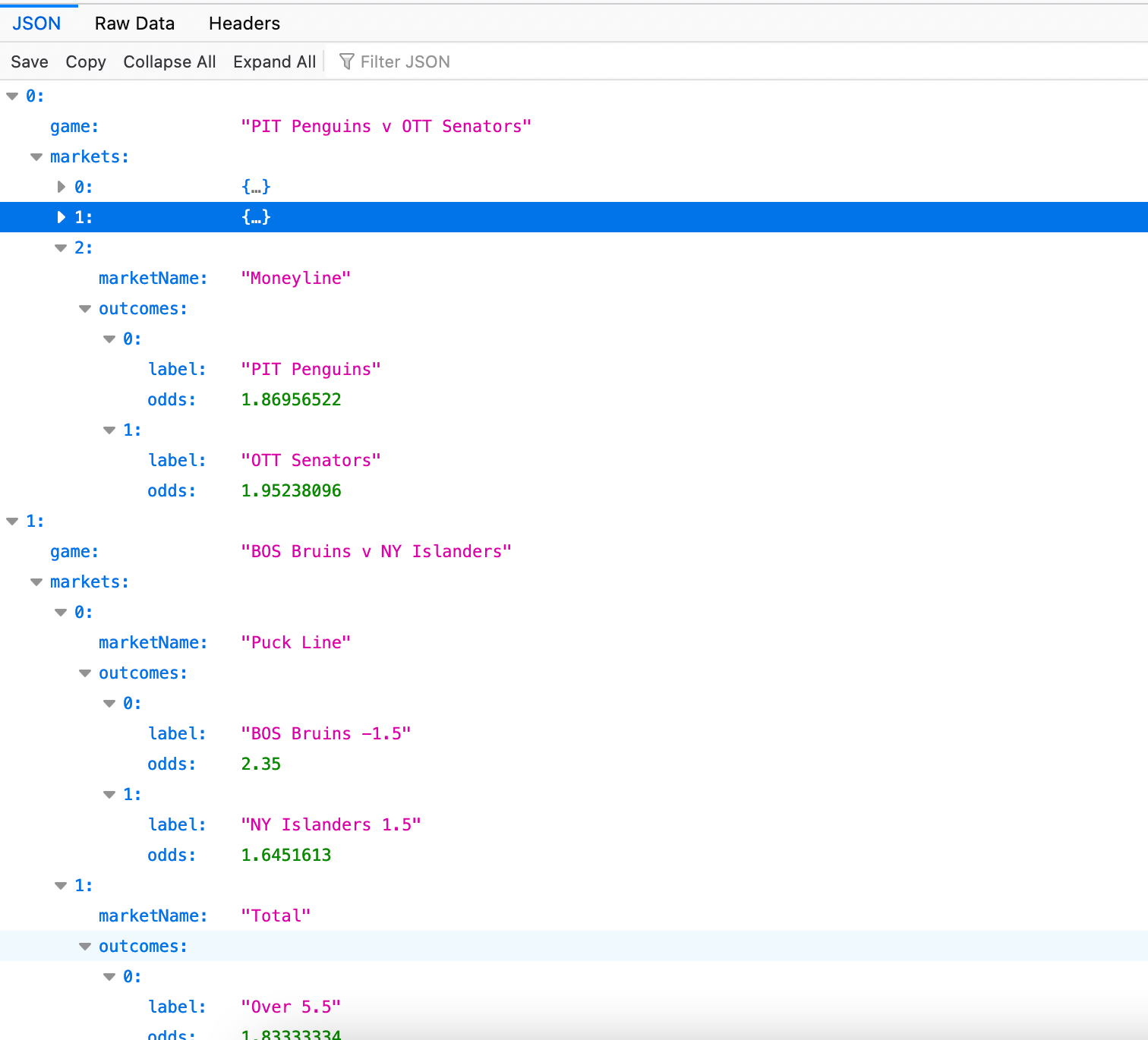
Conclusion
Thanks to the successful test, the pregame part of this project is now complete. We strongly suggest you try the current version of the scraper out!
Questions? Feel free to ask them in the comments section below.
BR-reminder: As a reader of this Substack you should have completed BR at least once [your own identity] at this point or you are falling behind. >$5 000 to earn by clicking some buttons and you are still sleeping on it?
Next week we’ll be back with more web scraping material, mainly focusing on the live odds scraping/streaming.
Update: Part 2 is out. You can find it here!
Until next time…
Does anyone know if this still part still works? I have been trying but can't seem to get it to work.