
Scraping time... Selenium too slow!
Level 5 - SHARP

Do you have a friend who likes betting and would like to sharpen his/her action? Help them on their path by sharing the BowTiedBettor Substack. Win and help win!
Welcome Degen Gambler!
Today we will extend our current web scraping knowledge by discussing new ways of gathering online information. In our first scraping post “Build your first odds scraper” we consulted Selenium to solve our problems, an open source umbrella project for a range of tools and libraries aimed at supporting browser automation. However, there two major disadvantages with Selenium:
It is slow.
It is unintuitive. You’re basically extracting data from arbitrary HTML sections containing elements with more or less ‘random’ names. This makes error checking/updating code unnecessarily difficult. Example below.
today_object = driver.find_element(By.CLASS_NAME, "_79bb0")
games = today_object.find_elements(By.CLASS_NAME, "f9aec._0c119.bd9c6")
for game in games:
team_names = game.find_elements(By.CLASS_NAME, "_6548b")
...What if instead we could find a way to get around this Selenium stuff, and do something more similar to what the website itself is doing? After all, the website is getting their data from somewhere, right? Rarely do things just magically appear.
Background
When you browse the web using a web browser, there’s quite a lot going on in the background. You click a button and the site is (hopefully) updated. That doesn’t happen out of nowhere. In fact, your click executes code with a set of different rules that ensure that what should happen does indeed happen. Someone has built an “on-click” function/method, which, as soon as it receives your click, sends a ‘message’ somewhere. This ‘message’ is then interpreted and handled by new chunks of code that when finished returns a new ‘message’ for the website to handle. Lastly, the returned ‘message’ is used to present the relevant information to the user.
To restrict the above very abstract/general setting into something more practical, we now consider what happens when you visit a sports betting website. Okay, so you’re betting the NHL and so you enter https:// unibet.com/sports/#sports-hub/ice_hockey/nhl into your address bar and hit enter. At this point a huge number of different ‘messages’ are sent and received across the World Wide Web in order to, for example, collect and manipulate information Unibet wants to display to the user. The result: the site loads and all the content (e.g. the odds for the upcoming games) becomes visible. Now here comes the interesting part, what if we could mimic this behaviour of the website and perform the same operations/communications to get access to exactly the content we are looking for?
Web Communication Protocols
Enter web communication protocols. Web communication protocols are a set of technologies used to communicate with web servers and transfer information across the internet. The degree to which users can interact with this information depends on the specific protocol being used. Some protocols are more interactive than others, allowing users to manipulate and customize the information they receive in various ways.
For sports betting purposes, there are two relevant protocols to be aware of, HTTP and WebSocket.
The HTTP protocol is a system used to transfer data over the internet. It consists of a client-server architecture, where requests are sent from a client to a server, and responses are returned in response to these requests. The protocol includes several components that work together to allow this data transfer to happen, including request messages, status codes, headers, and content types.
WebSocket is a communication protocol that allows two-way, realtime communication between clients and servers over the internet. WebSocket communication works by establishing a persistent connection (as opposed to the HTTP request-response structure) between a client and a server, allowing for seamless data transmission in both directions. This makes the protocol ideal for applications that require fast and efficient communication, such as live betting.
Basically, the bookmaker stores its odds/betting information on a server and when you are visiting and interacting with the website your browser sends HTTP requests and/or establishes WS connections to/with this server, then awaits responses containing the requested information and finally presents the data to the user. Hence, if we could learn the *basics* (no wizardry needed) of these communication protocols, we should be able to copypasta the requests/calls/messages and hopefully obtain the same data as the one we’re seeing on the website.
Note: We’re by no means any web scraping experts so if you’re reading this and find that something should be added/rephrased, please share your correction/clarification with the rest of our readers in the comments.
Let’s go!
Enough background information. Let’s scrape some odds!
As you could probably guess from the above section, we’ll be scraping the Unibet NHL odds. A quick check reveals that Unibet is utilizing the standard HTTP-protocol to transfer odds information, therefore we’ll go down the HTTP requests-response route today and return with WebSocket (slightly harder) material later down the line.
Our scraping material assumes you have some familiarity with Python. If you don’t, please get started today. Learning Python is definitely one of the most +EV decisions you can make if you’re even remotely interested in earning some WIFI-money. Combine Corey Schafer and Automate the Boring Stuff and you’ll soon be an excellent herpetologist.
We begin by installing the requests module in our environment by running
pip3 install requests in the terminal.
Next, head over to the site you want to scrape, in our case it’s https:// unibet.com/sports/#sports-hub/ice_hockey/nhl. Right-click, click inspect elements and head over to the ‘Networks’ tab in the web dev tools. Reload the page. Click ‘type’ in the menu and scroll down to json (a lightweight data-interchange format, easy for humans to read and write, easy for machines to parse and generate).
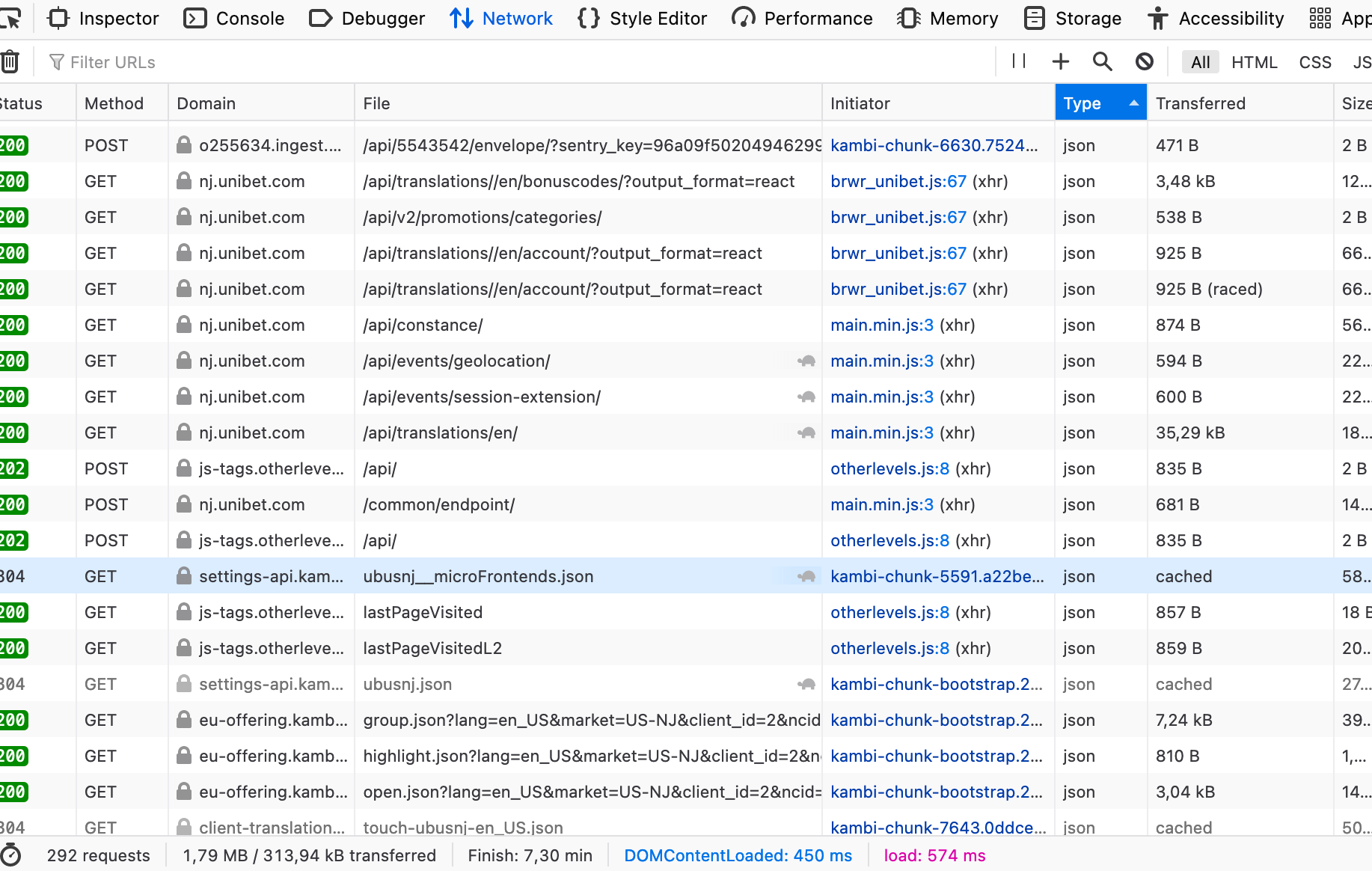
As you can see there are a lot of different objects here. We can either just go through them manually (doesn’t take too much time when you’ve done it a couple of times) or try to nail down the range somewhat by searching for terms such as “hockey”, “odds”, “api” in the manual “Filter URLs” bar. A search for ‘hockey’ yields
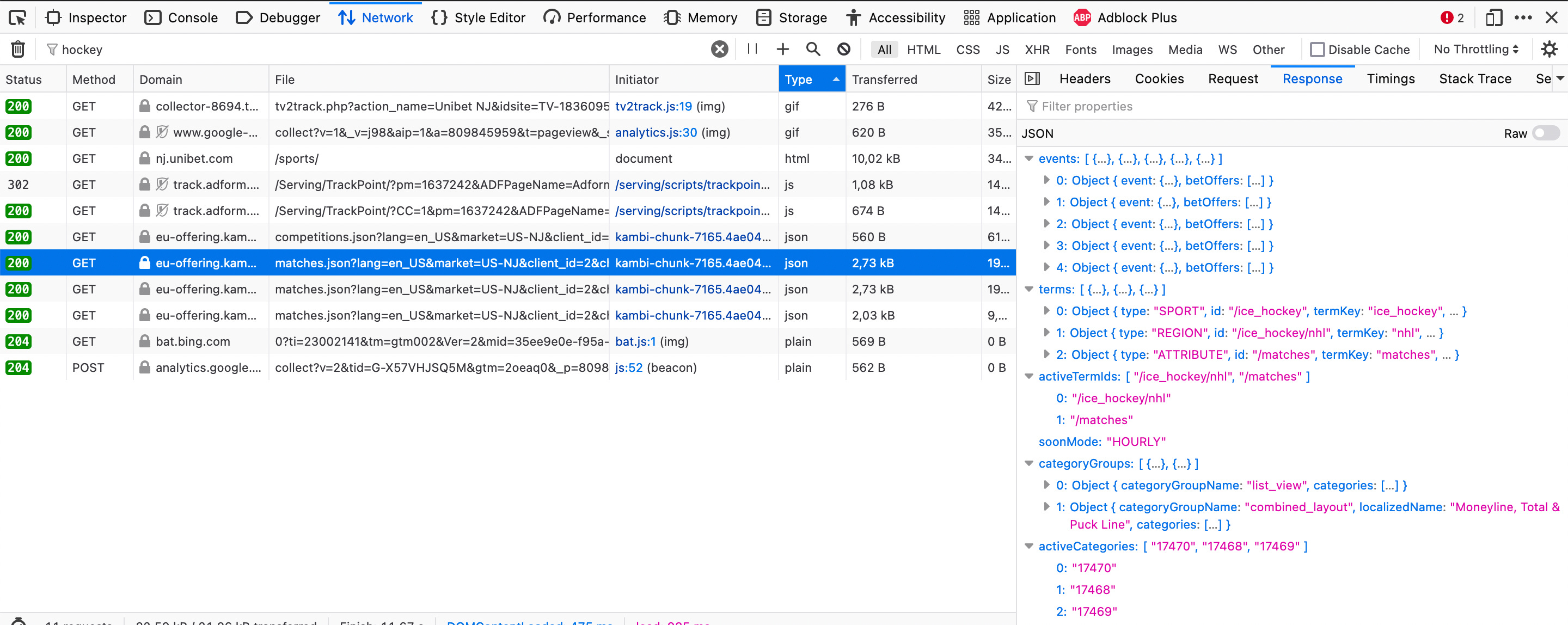
and clicking on response out at the right on one of the “eu-offering.kam…” requests, we note that this response seems to contain the information we are looking for. Use Firefox (Firefox has an excellent JSON-parser built into the browser) and go to the url [https:// eu-offering.kambicdn.org/offering/v2018/ubusnj/listView/ice_hockey/nhl/all/all/matches.json?lang=en_US&market=US-NJ&client_id=2&channel_id=1&ncid=1667115444478&useCombined=true&useCombinedLive=true] containing the JSON-response and click collapse all on the upper left. The games and the odds info for them are likely listed under ‘events’, so we click events and investigate one of the elements to see if we can find anything of interest.
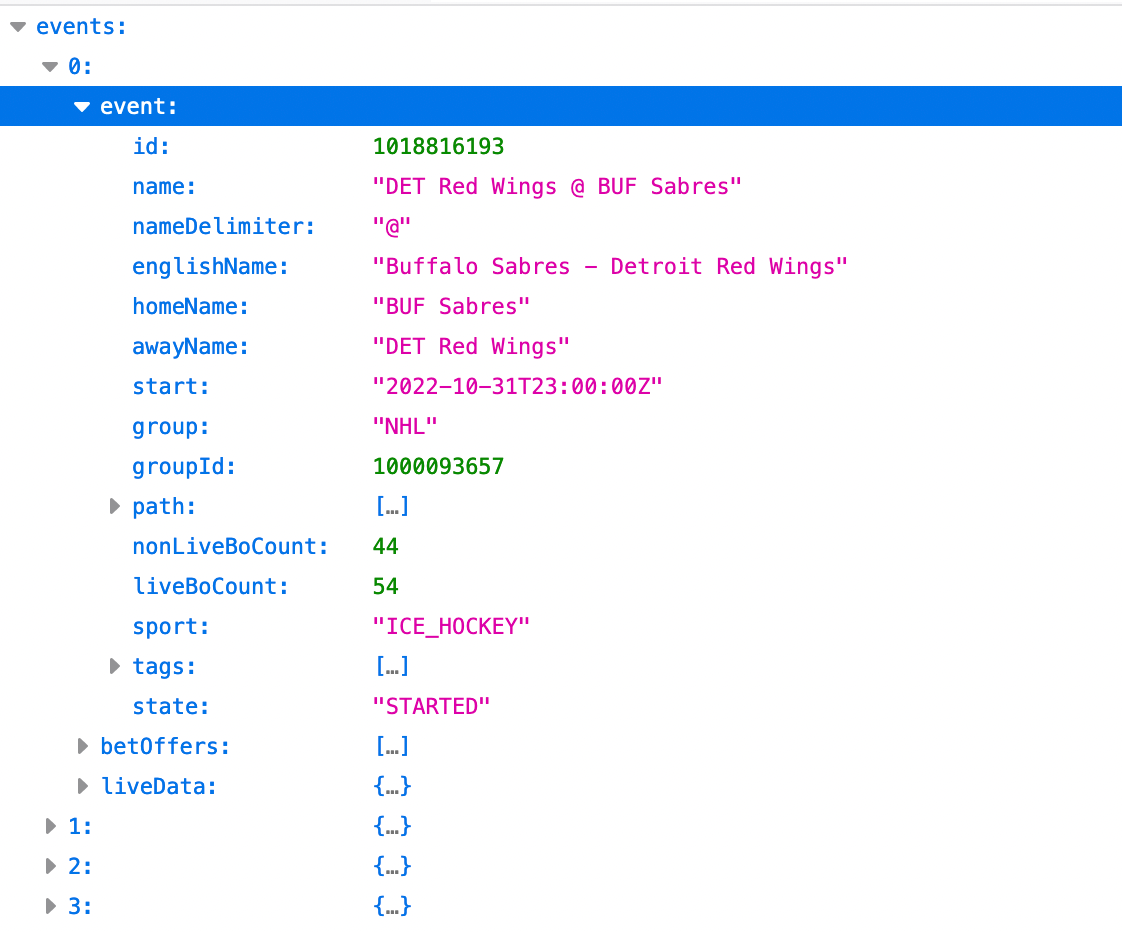
Indeed, for each event there appears to be three objects, ‘event’ that contains more general information regarding the game, ‘betOffers’ which holds the odds for the different available markets and ‘liveData’ which is updated with the latest information as the game progresses. Inspecting ‘betOffers’ we see that there are three markets offered for every game, "Puck Line - Inc. OT and Shootout", "Moneyline - Inc. OT and Shootout" and "Total Goals - Inc. OT and Shootout”.
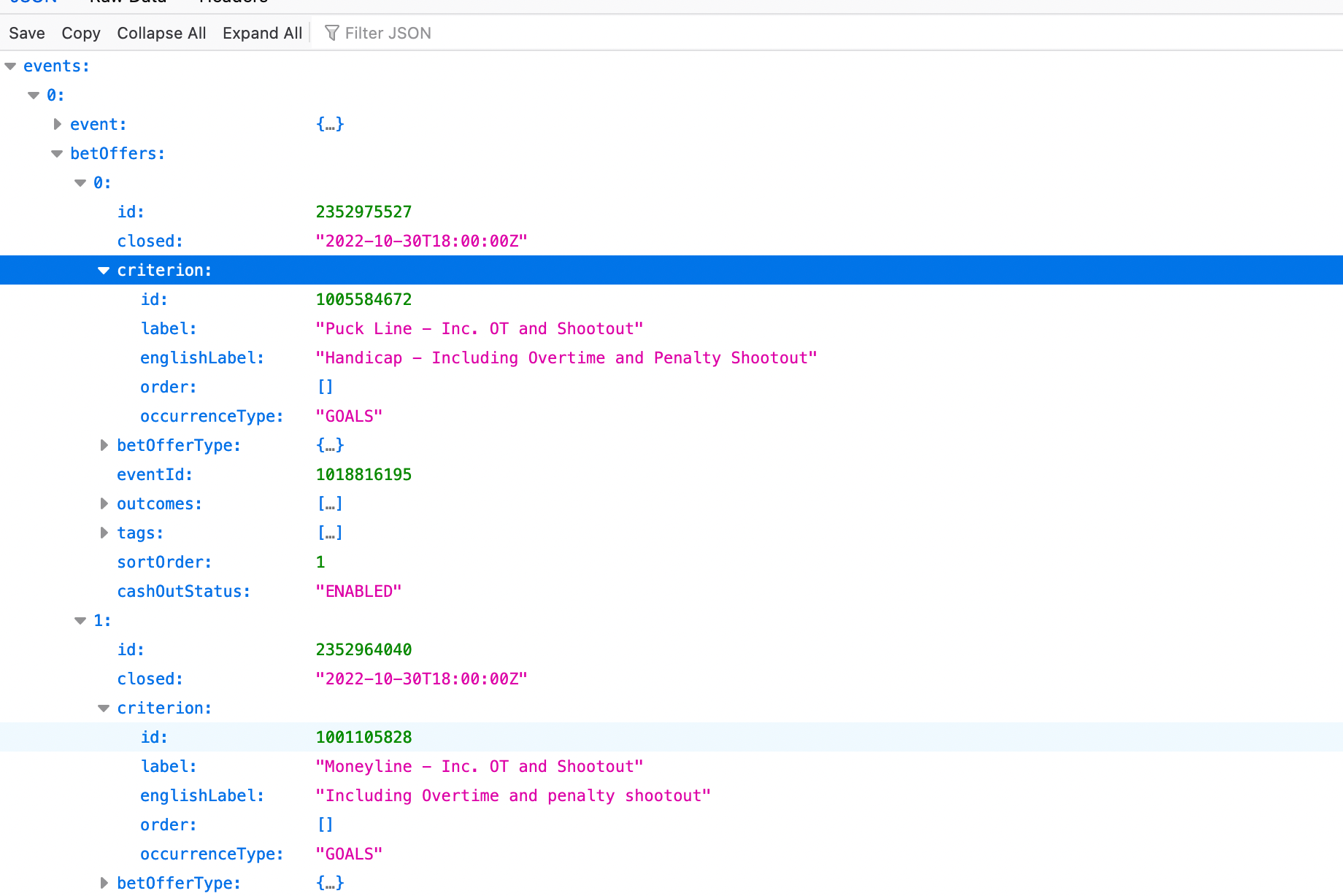
Now that we’ve analyzed the existing content, we’d like to extract a subset of it and save it locally to our computer for further use.
Suppose for simplicity we are interested only in the moneyline market odds and would prefer to exclude the games which have already begun. How do we proceed?
Since we’ve found the exact location (the URL above) for all the data related to Unibet’s NHL-odds, we can use the Python library requests and send a get request to this URL. This will return a Python requests.Response object containing all the information we’re interested in and by applying some relevant methods to this object we’ll hopefully be able to get job done. The below code sends the request and stores the response object in a variable we’ve chosen to name unibet_response.
import requests
unibet_response = requests.get("https://eu-offering.kambicdn.org/offering/v2018/ubusnj/listView/ice_hockey/nhl/all/all/matches.json?lang=en_US&market=US-NJ&client_id=2&channel_id=1&ncid=1667115444478&useCombined=true&useCombinedLive=true")Autist note: Sometimes authorization and/or more is required for a request to be successful. In this case you’ll want to check *exactly* which headers (a request header is a HTTP header that can be used in an HTTP request to provide information about the request context, so that the server can tailor the response) was sent in the get-request and then make sure to include those in the get request you’ll be sending in your Python script. Tools like Postman/Insomnia simplifies this process *a lot* by constructing correct requests for you.
If we now run the above code and do a print(unibet_response) and a print(unibet_response.text) we note that the request was successful and that the data we’ve obtained and stored in unibet_response appears to be the right one.
<Response [200]>
{"events":[{"event":{"id":1018816193,"name":"DET Red Wings @ BUF Sabres","nameDelimiter":"@","englishName":"Buffalo Sabres - Detroit Red Wings","homeName":"BUF Sabres","awayName":"DET Red Wings","start":"2022-10-31T23:00:00Z","group":"NHL","groupId":1000093657,"path":[{"id":1000093191,"name":"Hockey","englishName":"Ice Hockey","termKey":"ice_hockey"},{"id":1000093657,"name":"NHL","englishName":"NHL" ...Owing to the fact that the content we’re requesting is in JSON format, we may now use the json()-method on our unibet_response object to generate a Python dictionary containing all the information. Since we’re used to working with dictionaries this will simplify the remainder of the scraping process.
import requests
unibet_response = requests.get(
"https://eu-offering.kambicdn.org/offering/v2018/ubusnj/listView/ice_hockey/nhl/all/all/matches.json?lang=en_US&market=US-NJ&client_id=2&channel_id=1&ncid=1667115444478&useCombined=true&useCombinedLive=true")
unibet_dict = unibet_response.json()At this point we have everything we need contained in unibet_dict. Furthermore, it is a Python dictionary (which we know how to handle) following the exact same structure as the JSON data we’ve already spent some time analyzing. Therefore, we know quite a lot about how the information is stored and where to find the odds we're searching for.
To clarify: When you’re extracting the relevant data you’ll want to use a JSON-parser (for example the one built into Firefox) to efficiently be able to find the location of what you’re looking for. A
For example, if we’d like to print all the names of the games we can store the list of games in a variable named games and then loop through this list and print the name of the game at each iteration. The below code helps us out with this exact thing.
import requests
unibet_response = requests.get(
"https://eu-offering.kambicdn.org/offering/v2018/ubusnj/listView/ice_hockey/nhl/all/all/matches.json?lang=en_US&market=US-NJ&client_id=2&channel_id=1&ncid=1667115444478&useCombined=true&useCombinedLive=true")
unibet_dict = unibet_response.json()
games = unibet_dict['events']
for game in games:
print(game['event']['name'])It returns
LA Kings @ STL Blues
VGS Golden Knights @ WSH Capitals
OTT Senators @ TB Lightning
PHI Flyers @ NY Rangers
BOS Bruins @ PIT Penguins
MTL Canadiens @ MIN Wild
NY Islanders @ CHI Blackhawks
LA Kings @ DAL Stars
NSH Predators @ EDM Oilers
SEA Kraken @ CGY Flames
NJ Devils @ VAN Canucks
FLA Panthers @ ARI Coyotes
ANA Ducks @ SJ Sharkswhich seems correct.